Doğru model, doğru işte. Ölçülerek.
UTOPIX AI tek bir modele bağlı değildir — model havuzunu yönetir, ajanları geliştirir ve kaliteyi gerçek sahada ölçer.
Tek modele mahkûm değilsiniz.
Generation, embedding, yeniden sıralama ve vektör arama — her katman için sağlayıcı seçilebilir.
Sağlayıcı Tabloları
Generation, Embedding, Reranker ve Vektör Arama — dört ayrı sağlayıcı tablosu, ortak standartla yönetilir.
API Tanımları
Tüm sağlayıcı anahtarları tek ekranda. Claude, GPT, Gemini, Qwen, Cohere, Voyage ve daha fazlası.
Otomatik LLM Güncelleme
Yeni model çıktığında sistem keşfeder, doğrular ve kataloğa ekler — siz takip etmek zorunda kalmazsınız.
Yerel & Bulut Seçeneği
Modeli buluttan ya da kendi sunucunuzdan çalıştırın. İstenirse tüm sistem kapalı devre — veri kurumdan çıkmaz.
Ana & Yedek Model
Her ajana ana ve yedek model. Ana model hata verir veya kotası dolarsa sistem otomatik yedeğe geçer.
Ajanlar da yetişir, terfi eder, gelişir.
Gerçek bir organizasyon gibi: kademeler, gelişim döngüsü ve minimum maliyetle yetişen bir ekip.
Ajan Sepeti
Bir göreve birden çok aday model. En uygun maliyet/başarı dengesini sistem önerir.
Uzman Yardımcısı → Uzman → Müdür
Üç kademe, üç model gücü. Rutin iş yardımcıya, karmaşık iş uzmana, yeni muhakeme müdüre.
Mimar / İşçi Modeli
Müdür ajan zoru bir kez çözüp şablona döker; Uzman ve Yardımcı onu ucuza tekrarlar.
Gelişim Döngüsü
Ajan kendi geçmiş işlerini değerlendirir, öğrendiğini içselleştirir — her döngüde biraz daha iyi.
Terfi & Beyin Yükseltme
Performansı yükselen ajan terfi eder; daha güçlü bir modele (beyne) taşınır.
Tahmin etmeyin — ölçün.
Hangi model, hangi combo gerçekten işe yarıyor? UTOPIX bunu sahada kanıtlar.
Teorik & Fiili Performans
Görevin teorik süresi ile ajanın fiili performansı yan yana — gerçek verim görünür.
Ajan Yarışması
Aynı görevi birden çok modele verin; hız, kalite ve maliyet metrikleriyle karşılaştırın.
Uçtan Uca Pipeline Yarışması
Bileşen değil ZİNCİR testi: reranker + LLM birlikte, gerçek soru + bilinen doğru cevapla skorlanır. Zayıf halkayı gösterir.
Benchmark Karşılaştırma
Genel benchmark'lar değil — kendi sorularınız, kendi verinizle. Saha gerçeğini yansıtan ölçüm.
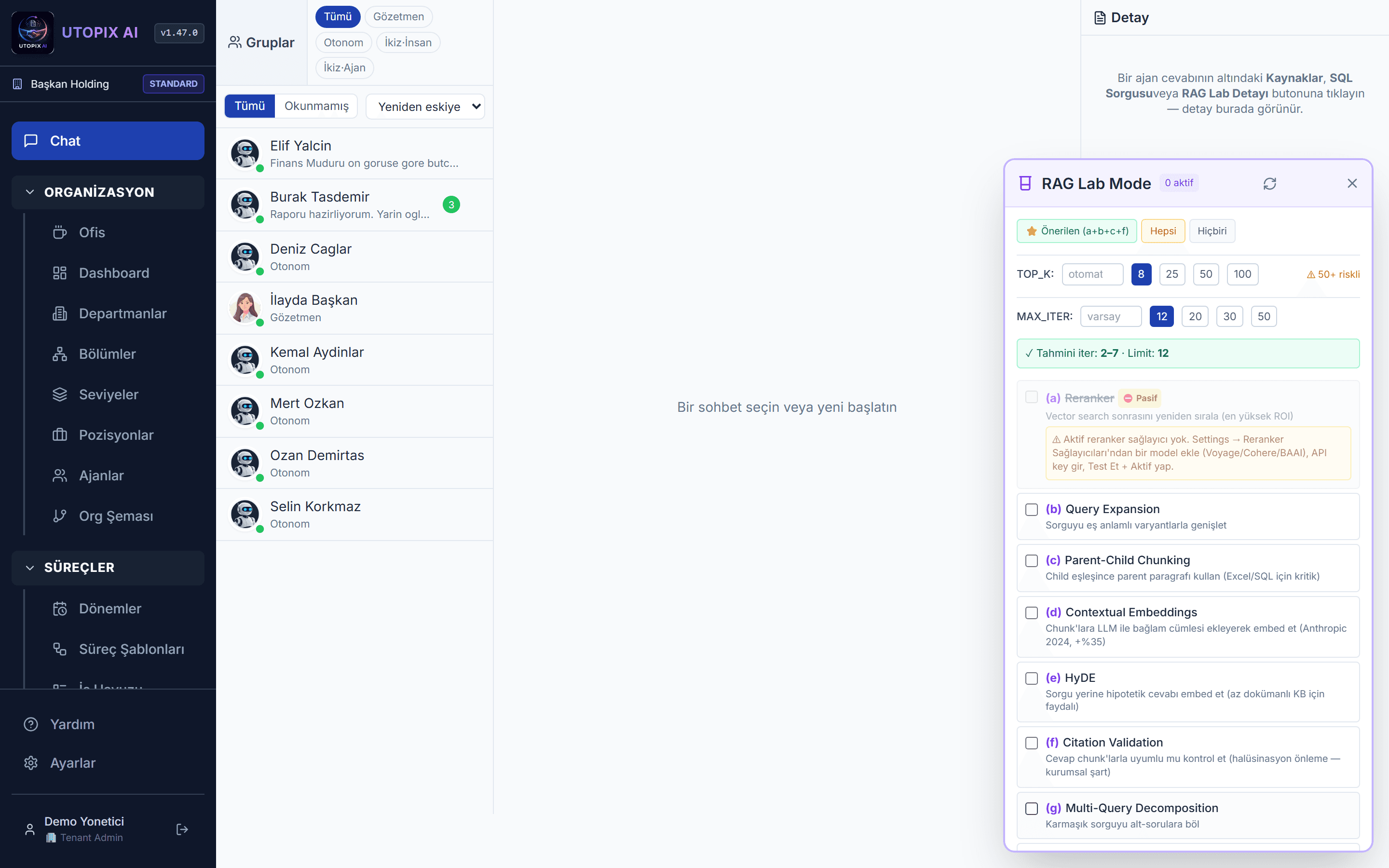
8 Teknikli RAG Laboratuvarı
Hibrit arama (BM25 + vektör RRF), yeniden sıralama, bağlam optimizasyonu ve daha fazlası — her cevabın hangi teknikle, kaç iterasyonda üretildiği şeffaf raporlanır.
SQL Performans Denetçisi
Kütüphanenizdeki sorguları yürütme planlarıyla denetleyen yapay zekâ hakem: yavaş sorgu, eksik indeks ve riskli desenler raporlanır.
Şeffaf Maliyet Kalibrasyonu
Tahmini değil gerçek maliyet: sağlayıcı faturalarıyla iki-oranlı (girdi/çıktı) kalibrasyon. Model kataloğu yalnız resmî sağlayıcı dokümanlarından doğrulanmış kimliklerle çalışır.